At Apollo, we’re building an AI Assistant designed to be more than just a chatbot. It’s a context-aware interface that can execute complex workflows and seamlessly integrate with Apollo’s ecosystem. From querying data and triggering API calls to orchestrating UI actions, the Assistant functions as an intelligent layer on top of Apollo’s platform.
But as anyone who has worked with AI agents knows, power and complexity go hand in hand. During the early days of development, we faced a critical challenge: how could we test and iterate quickly on such a dynamic, multi-agent system without breaking trust in the reliability of the actions it takes on behalf of the user?
The answer became our AI Assistant Evaluation Regression Suite (ARS), a custom-built framework that transformed fragile manual testing into automated, conversation-driven evaluations, helping us test every release with awareness of real-world side effects.
Why ordinary evals failed us 🧵
Most evaluation frameworks are built for a simple world: you give an AI a prompt, it gives you a single text response, and you check if that response matches what you expected. But our Assistant isn’t that simple.
- It’s a conversation, not a one-shot question
Our AI doesn’t just answer once, it talks back and forth. Think of it like chatting with a teammate: what you say in the first message affects how they reply to the second. That’s what multi-turn conversations mean - the context builds up, and earlier exchanges shape later ones. - It “walks” the “talk”
Our Assistant can call backend APIs (for example, searching people living in US) and update frontend widgets (like showing data in currently loaded tabular views). So we’re not just testing the language-based outputs but also the "actions taken" from the executed user journeys. - Even “deterministic” models become “indeterministic”
We know it well that when the temperature of the LLM is set to 0, it doesn’t guarantee that the outputs will be 'identical' each time.
Ask “How was your day?” twice, and you might get:“Pretty good, thanks!”
Different wording, same meaning (semantically same).
“Good day overall, appreciate you asking.”
A plain string comparison thinks they’re different, but humans know they’re not. - Multiple cooks in the kitchen
Several teams were updating prompts and logic simultaneously. For example, we were adding capabilities like workflow management, deliverability and enrichment capabilities as well as analytical insights together.
The bottom line - we needed a system that:
- Ignored harmless phrasing differences
- Checked for correctness strictly when it mattered
- Covered the full workflow, not just what the AI said
The core idea: Test using real conversations 💡
Each AI conversation at Apollo.io is built from multiple structured layers that together define both user intent and assistant behavior:
-
User Message
The natural-language instruction from the user (e.g., “Find people living in the US”). It anchors the intent and triggers the assistant workflows. -
Assistant Thoughts
Invisible system operations where the assistant interprets the request, decides which APIs to call, and applies reasoning. These steps capture internal actions like “Applying filters…” or “Fetching analytics…”. In the background, it makes use of different backend and external API calls augmented with the power of LLM to work its magic ✨ -
Assistant Frontend Widgets
The visible, structured UI output (e.g., search filters, charts, reports). These are machine-generated visual components that the users can interact with. -
Assistant Response (Text Output)
The natural-language explanation accompanying the UI, provides results and context. It ties the backend action and frontend view into a human-readable conclusion.

These are serialised into a “Sample Ideal Conversation” and stored in a Test Repository. These specified tests are replayed later against the live assistant. If the assistant preserves intent, calls the right APIs with acceptable parameters, and produces the expected UI effects, the test passes. Otherwise, CI fails and the change doesn’t ship.
System architecture 🛠️
A repository of ideal conversations
Instead of manually writing tests from scratch, developers can run a standalone script taking a real conversation as input that demonstrates the behavior they want to preserve. The script acts like a sophisticated recording device. It replays the conversation message by message, watching as the assistant processes each one, and quietly captures everything happening behind the scenes: every API call made, every response generated, and every decision taken.
Once the conversation completes, all this captured data gets packaged into a test file and added to the repository, creating a perfect snapshot. This snapshot can be replayed anytime to test if the assistant still behaves correctly and acts as a regression spec. What would normally take hours of tedious manual work happens automatically, turning real-world interactions into reliable safety nets that catch bugs before they reach users.
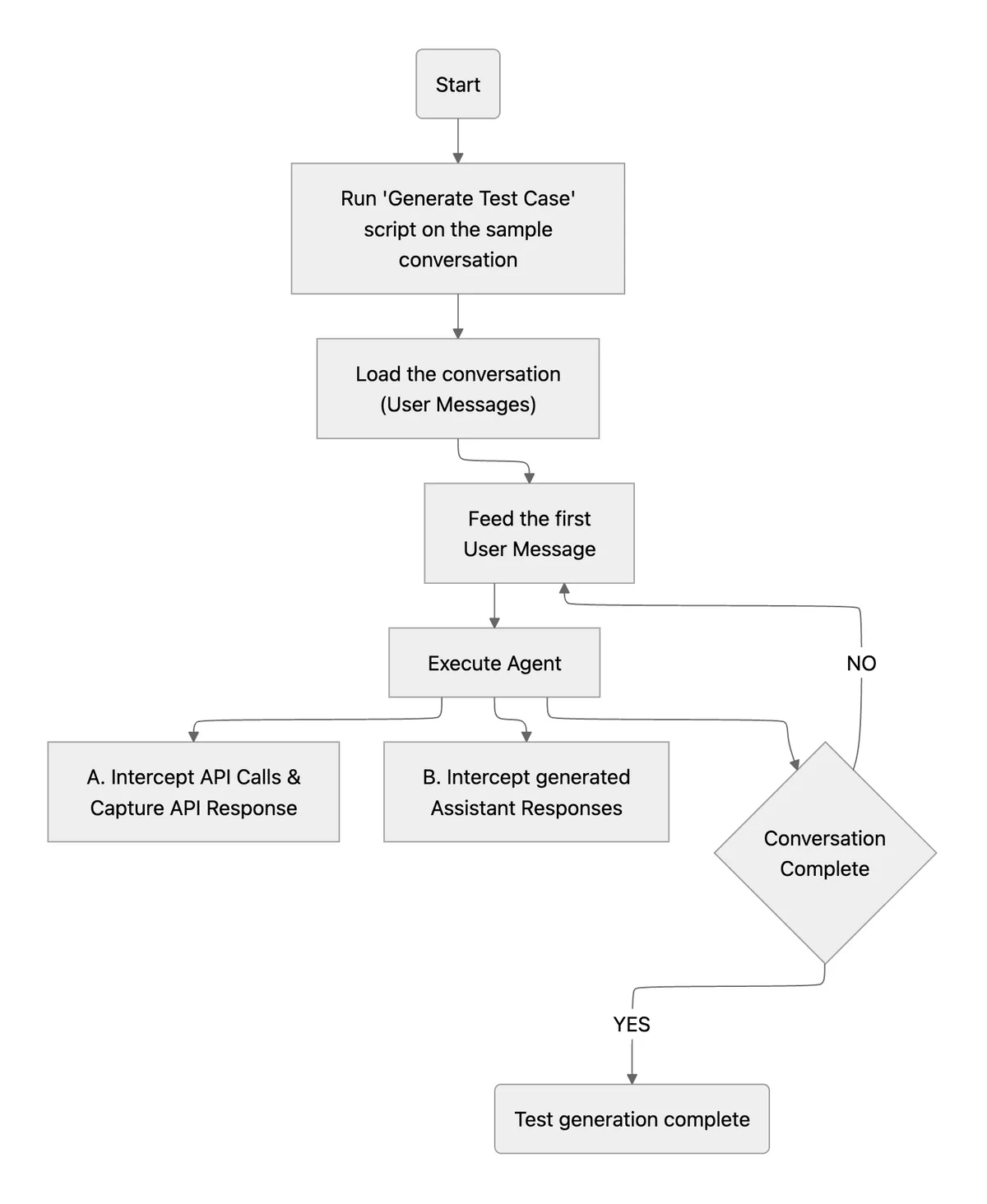
The output of this process yields a fully specified, context-aware “gold” conversation - capturing user messages, assistant replies, and all associated side effects (like API calls, UI actions, or variable updates) in a replayable format that preserves both semantics and execution flow.
Running Regression Tests
Once the test repository is ready, we can automatically validate it against the live assistant or the current code version using CI triggers. The process runs fully unattended verifying each stored conversation, one message turn at a time.
- CI Trigger and Test Distribution
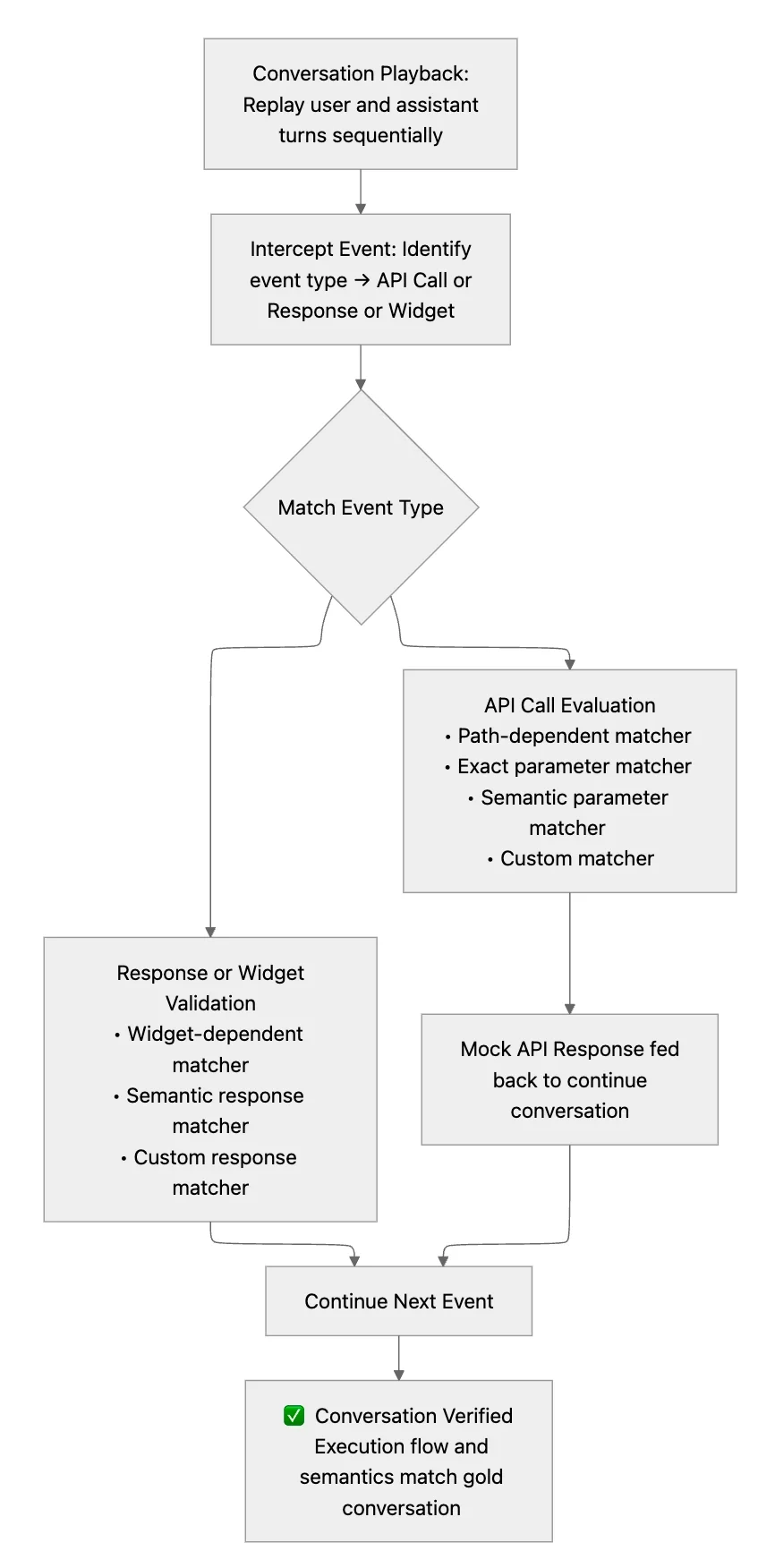
A CI trigger starts the regression suite whenever a new build, model, or prompt update is deployed. EachPytestworker pulls a batch of Sample Ideal Conversations from the Test Repository, ensuring parallel execution across the suite. - Conversation Playback
For every test case, the worker replays the conversation in order:
a. Feed the first (or next) user message into the assistant.
b. Intercept all resulting API calls, widget generations, and responses.
c. Compare each event against its expected counterpart from the test case.
This step-by-step replay ensures that both execution flow and semantic outcomes match what’s defined in the gold conversation. - API Call Evaluation
Each intercepted API call is routed through layered matchers:
a. Path-dependent matcher → Confirms endpoint and HTTP method
b. Exact parameter matcher → Ensures argument fields match exactly for the given API Calls made
c. Semantic parameter matcher (LLM-based) → Allows meaning-preserving flexibility. For example, the expected response values match semantically to generated response values.
d. Custom matchers → Handle domain-specific tolerances. For example, the expected response can have the same keys as the generated response but not the same values.
If a call matches successfully, a mock API response from the repository is fed back so that the conversation can continue seamlessly. - Assistant Response Validation
Generated assistant responses and widgets go through a similar pipeline:
a. Widget-dependent matcher checks component type, structure, and parameters.
b. Semantic response matcher verifies the assistant’s reply preserves the same intent and factual content.
c. Custom response matchers cover specialized UI or formatting variations -
Pass/Fail Determination
After every message turn:- If all API calls and Assistant responses pass their matchers, the flow moves to the next user message.
- If any check fails, the test case is marked “Fail” and the script captures an actionable diff showing what diverged.
When all message turns pass, the conversation is marked as “Pass.”
-
CI Reporting and Visual Overview
At the end of the run:- Passed and failed conversations are summarised.
- Any semantic or structural drift is highlighted with detailed diffs:
- Deviated API parameters
- Unsatisfied semantic matchers
- Mismatched widget properties
This allows developers to pinpoint the exact change in assistant behavior before it reaches production.
The Results: Confidence, Speed, and Big Gains 🏆
- The accuracy of the AI Assistant in providing responses nearly doubled from 34% to 76.7%
On a 30-conversation set benchmark, semantic and functional validation closed the gap between “it seems right” and “it is right.” - Development velocity soared.
With reliable automation catching only real regressions, engineers stopped firefighting false negatives and started shipping confidently. Teams could iterate faster, knowing every change was backed by trustworthy tests. - Large-scale rewrites became routine.
In just four weeks, we shipped three major overhauls including LLM updates, provider migrations, and architecture refactors, all protected by automated regression tests.
What we Learned 🧠
Looking back, a few key insights stand out:
- Automate with intelligence. Semantic matching was the breakthrough. Without it, evaluation remained noisy and brittle.
- Ground tests in reality. By pulling test cases from real conversations, we made sure evaluations were always relevant.
- Quality must be enforced; it's not optional. CI gating created accountability: regressions couldn’t sneak into production.
- Invest in evaluation early. While it felt like a heavy lift early on, building this regression suite saved exponentially more time and pain down the line.
What’s Next 🚝
We’re not stopping here. Current efforts are focused on:
- Speeding up runs (from 10 minutes to near-instant feedback).
- Expanding coverage with more diverse conversation sets.
- Improving Developer Experience for triaging failure cases well
Each improvement shortens the feedback loop, enabling us to iterate even faster while keeping the AI-Assistant’s behavior consistent and trustworthy.
🔮 Looking Ahead - Join Us At Apollo!
The Apollo AI-Assistant is built to be ambitious - a system that understands users deeply, acts across surfaces, and grows in capability with every release. But ambition without reliability is a recipe for frustration. By building a custom regression framework, we gave ourselves the tools to scale confidently. What once felt like a fragile experiment is now a robust platform we can evolve rapidly without fear.
We would love for smart engineers like you to join our "fully remote, globally distributed" team. Click here to apply now!