Enhancing Prospect Recommendations with Team Collaboration and Index Optimization
At Apollo, we are committed to continuously improving our machine learning models to enhance user experience and optimize system efficiency. In this blog post, we will take you through the journey behind our recent update to the Prospect Recommendations model.
This update significantly expanded recommendation coverage, reduced system costs, and maintained high accuracy, ensuring our users received better, more personalized prospect suggestions.
Previous Recommendations Model
When you log in to Apollo, you may see recommended prospects directly on your home page.
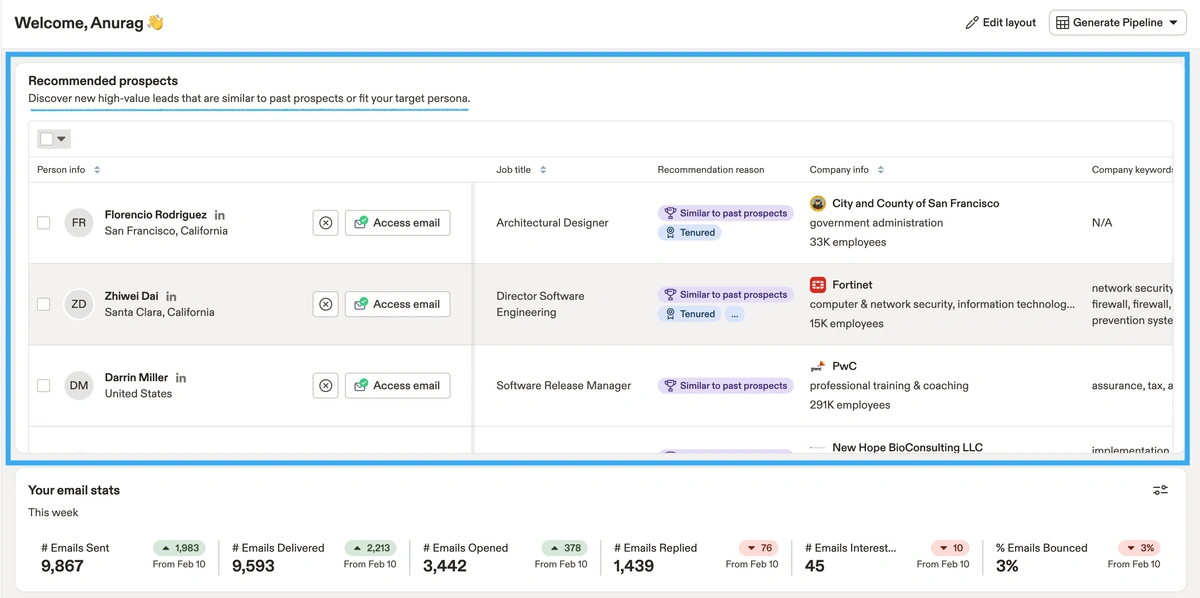
Additionally, you can discover recommendations from within a company on that company's ID page.
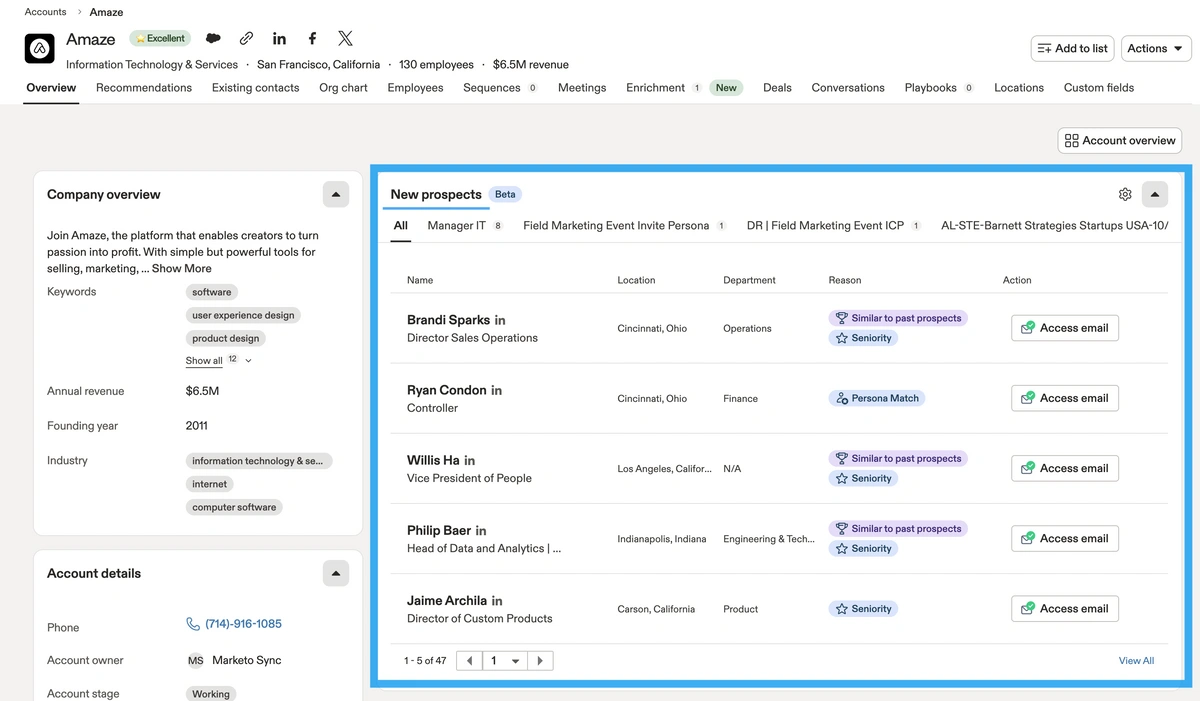
These recommendations come from two primary sources:
- Prospects that match the personas you (or someone on your team) have created.
- Prospects generated by our recommendation engine, which are labeled as “Similar to past prospects.” These are determined based on historical user data.
Understanding the Collaborative Filtering Model
Our recommendation engine is powered by a collaborative filtering model, a widely used technique in recommendation systems. Collaborative filtering works by analyzing past user interactions and identifying patterns that help predict future behavior. The fundamental idea is that users who have engaged with similar prospects in the past are likely to be interested in similar prospects in the future.
To achieve this, we represent both users and prospects as high-dimensional vectors. The user’s vector captures their historical preferences, while the prospect vectors encode their attributes based on prior interactions. These vectors are stored in a vector index, allowing us to quickly search for and retrieve the most relevant prospects based on similarity scores. Similarity is computed using the dot product between the user’s vector and each prospect vector—higher dot products indicate stronger relevance. While this method enables efficient recommendations, it also introduces challenges such as increased storage and computational costs as the index grows over time.
Challenges with the Previous Model
While our previous recommendation model was effective in many cases, it had two major limitations:
- Limited Coverage: Users with minimal historical prospecting data often received no recommendations. This issue was especially prevalent for newer users or those with sporadic prospecting activity.
- High Computational Costs: The model stored all available prospects in a vector index to facilitate quick retrieval. However, as the index grew in size, it led to increased storage costs and slower retrieval speeds, negatively impacting efficiency.
Key Enhancements in Prospect Recommendations 2.0
Leveraging Team-Level Data for Improved Coverage
For users with little to no historical prospecting activity, we sought to leverage the collective intelligence of their team members. Initially, we experimented with a team-level model that created a single representation for the entire team. While this significantly improved coverage—achieving 100% coverage for teams on Pro/Custom plans—and increased team-level accuracy to 97% precision@100 (up from 81%), it compromised the personalization of individual users. Since all team members shared the same recommendations, the model struggled to distinguish user-specific preferences, resulting in a significant drop in personal recommendation accuracy to 39% precision@100.
To balance personalization and broader insights, we took a different approach: incorporating team-level data at a reduced weight (0.5x). This meant that while recommendations still prioritized the user’s own historical activity, they also took into account the activity of teammates, albeit with a lower influence. This method effectively increased the size of the training dataset without overwhelming the model with non-personalized data. The results were impressive:
- Improved Coverage: By leveraging team-level data, the model’s ability to make recommendations increased significantly. The proportion of paid users (Pro/Custom plans) receiving recommendations increased from 78% to 94%.
- Maintained Accuracy: Despite a 280% increase in dataset size—from 9.5B to 29.3B data points—precision@100 improved from 81% to 84%, ensuring recommendations remained both relevant and personalized.
Optimizing the Vector Index for Efficiency
In addition to improving coverage, we also needed to address the issue of high storage costs and computational overhead caused by the large vector index. Here’s how we approached it:
- Analyzing Vector Magnitudes: The vector index stored a numerical representation of each prospect. The magnitude of a vector reflects how “strong” its representation is in the recommendation space. Prospects with lower vector magnitudes contribute less to meaningful recommendations because their dot product values with user vectors tend to be lower. Simply put, these prospects are less likely to be recommended to any user.
- Threshold Selection: To determine an effective threshold for removing low-impact prospects, we examined the distribution of vector magnitudes. We found that the 90th percentile of vector magnitudes was 0.6. This meant that a large portion of stored prospects had minimal impact on recommendations. By removing these low-magnitude prospects from the index, we were able to reduce its size by 10x, significantly cutting down storage and computation costs.
- Ensuring Minimal Accuracy Loss: Any reduction in the index size comes with a risk of losing valuable recommendations. To measure this impact, we analyzed precision@100, a key accuracy metric. We observed only a minor drop from 84.7% to 84.3%, confirming that removing low-magnitude prospects had no significant effect on recommendation quality while drastically improving efficiency.
Results
The implementation of these enhancements led to remarkable improvements:
- Greater Coverage: The proportion of users receiving high-quality recommendations increased significantly, contributing to a 25% rise in WAU, reaching 11,600.
- Lower Costs: The optimized vector index reduced storage and computational expenses by 25%, running into the range of thousands, making our system significantly more cost-efficient.
- Maintained Accuracy: Despite significant changes, the model continues to provide users with personalized and relevant recommendations.
Conclusion
This update was a testament to how strategic enhancements in machine learning models can lead to significant performance and efficiency gains. By incorporating team-level data in a controlled manner and optimizing the vector index for storage efficiency, we successfully enhanced the user experience while reducing system overhead.
We are excited about these improvements and will continue to refine our recommendations model to provide even better results. Stay tuned for more updates as we keep innovating!
🚀 .....and we are hiring!
Apollo solves numerous problem statements like these, and we are heavily investing in AI to develop products for our customers. As an AI native org, we leverage and tune AI to build cutting-edge solutions for our customers to make their GTM motions seamless, efficient, and cost-effective at scale (we are talking several billions here!)
We would love for smart engineers like you to join our "fully remote, globally distributed" team. Click here to apply now!