Overview
At Apollo, our mission to build a leading Sales Platform brings with it a variety of complex customer use cases. Our goal is to support these use cases in the most intuitive and user-friendly manner possible.
One such intricate challenge is enabling searches across multiple Apollo entities within different contexts. Apollo's system comprises numerous entities that users interact with across various surfaces, including:
- People
- Companies
- Contacts
- Accounts
- Job Openings
- Emails
- Phone Calls
- Meetings
- And more.
In this blog, we will explore how Apollo meets the challenge of delivering robust, accurate, and high-performance search capabilities across these entities.
The Problem
Apollo leverages Elasticsearch (ES) as its primary search database. Most customer data is indexed within ES clusters to facilitate quick and efficient access, particularly when searching through various filters supported by Apollo.
However, each entity is connected to multiple others through different types of relationships, such as:
- Employment History: Person1 works at Company1 and previously worked at Companies 2, 3, and 4.
- Contact Creation: Contact1 was created from Person1 when they worked at Company2.
- Account Association: Contact1 belongs to Account2, which was created from Company2.
- Email Correspondence: Email1 was sent to Contact1.
- Meeting Participants: Meeting1 included Contact1, Contact2, and Contact3.
Our customers often need to query entities based on these relationships. Some common examples include:
- Find all individuals working at organizations with at least 50 employees.
- Identify contacts who have changed jobs since they were first saved.
- Retrieve all of my emails sent to contacts employed at CompanyX.
- Locate contacts associated with accounts in the ‘cold’ stage.
In traditional database systems, such queries would involve cross-table JOINs. However, due to additional requirements such as result ranking, full-text searches, and queries on arbitrary fields, Apollo does not use traditional relational databases. Instead, in ES, each entity is stored in its own index, making cross-entity searches difficult since ES lacks native support for JOIN operations.
Work Arounds
To enable JOIN-like queries in ES, there are two primary approaches:
1. Data De-normalization
This method involves embedding related objects directly within the parent object. While effective, it incurs high storage overheads and necessitates complex update propagation when embedded data changes at the source.
2. Multi-Query Join
Here, we query Index1, retrieve matching results (their IDs), and use those IDs to filter Index2, along with additional criteria. While this approach avoids storage redundancy, it becomes inefficient when the number of matched results in Index1 exceeds a few thousand.
Apollo has historically used both techniques, but as the company scaled in customer volume and data complexity these methods became bottlenecks that limited performance and feasibility.
The Solution
In search of a long-term solution, we explored various alternatives. Our research led us to Siren Federate, an Elasticsearch plugin developed by Siren.
This plugin provides the exact capabilities we needed, allowing us to execute cross-entity queries efficiently while leveraging ES’s existing infrastructure.
What is Siren Federate?
Siren Federate operates by bringing computation closer to the data, optimizing queries using ES’s inherent data topology. The architecture integrates seamlessly within the ES cluster, as illustrated below:
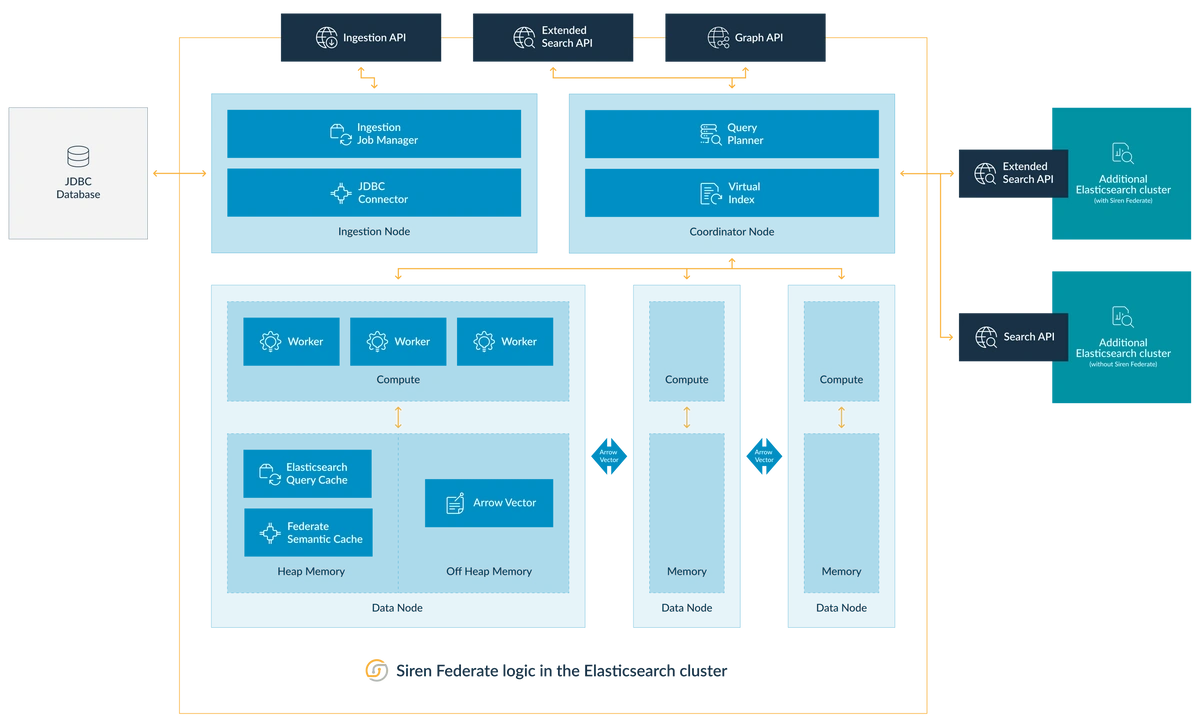
Key Technologies Used:
- Apache Calcite – Facilitates advanced query planning.
- Apache Arrow – Serves as the data format for off-heap storage.
These technologies make Siren Federate both reliable and scalable for our use case.
Implementation Strategy
Our adoption of Siren Federate followed a structured 3-step approach:
1. Feasibility Analysis
- Functional Completeness – Ensuring the plugin could handle our core search use cases.
- Performance Benchmarking – Verifying response times within acceptable latency limits (< 5s).
- Financial Viability – Evaluating licensing costs.
- Leadership Buy-In – Establishing success criteria for a trial phase.
2. Proof of Concept (PoC)
- Conducted initial validation using a trial license from Siren.
- Executed test queries with JOINs to assess performance.
- Performed load testing across varying data volumes and concurrency levels (details in Part 2).
3. Production Rollout
- Deployed Federate within our ES infrastructure (requiring rolling restarts).
- Scaled infrastructure to allocate sufficient CPU/memory for Federate without impacting ES performance.
- Implemented a phased rollout to customers.
Current State
Today, Siren Federate powers 100% of our JOIN-based queries in production and operates reliably at scale. While we faced minor hiccups initially, the Siren team worked closely with us to fine-tune configurations, enhance resilience, and optimize for our cluster topology.
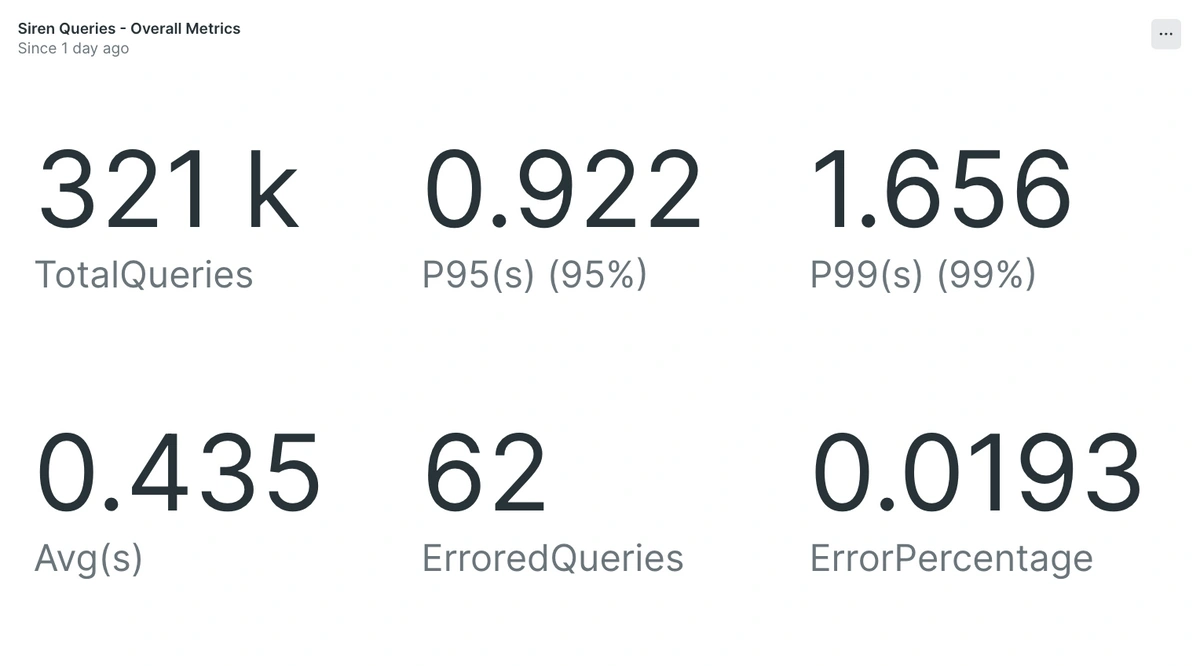
Here is a video testimonial shared by the Apollo Team to the Siren Team.
This concludes Part 1 of our blog series. In Part 2, we will delve deeper into:
- How we structured a feasibility analysis to convince senior leaders
- Performance optimizations for Siren Federate.
- Key configuration settings that impacted results.
- Resource distribution between Federate and ES within our infrastructure.
Stay tuned for Part 2!